
An Introduction to Kafka and Samza for Stream Data Processing
Kafka and Samza, developed by Apache Software Foundation, process real-time data like location data from Uber. Kafka feeds raw data to a distributed queue, and Samza performs tasks like Uber passenger-driver matching.
In which cases should we use Kafka and Samza?
By leveraging the scalability of a stream processing cluster, Kafka and Samza excel at handling high-volume and low-latency data streams. They are well-suited for processing real-time data collected by IoT devices or as a part of an OLAP system.
Kafka is a distributed event streaming platform that is used for building real-time data pipelines and streaming applications. It is commonly used for collecting, storing, and processing large amounts of data in real-time.
Kafka as a Messaging System
Kafka is a messaging system that allows different parts of a distributed system to communicate with each other. It follows a publish-subscribe pattern, where data producers publish messages without knowing how they will be used by the subscribers. This allows for decoupling between producers and consumers.
Consumers can express interest in specific types of data and receive only those messages. Kafka uses a commit log, which is an ordered and immutable data structure, to store and persist the data. However, as a user of Kafka, you don't need to worry about these technical details.
Broadly speaking, the main advantage of Kafka is that it provides a central data backbone for the organization. This means that all systems within the organization can independently and reliably consume data from Kafka. It helps in creating a unified and scalable data infrastructure.
Samza, on the other hand, is a stream processing framework that is built on top of Kafka. It provides a way to process data streams in real-time and is designed to handle high-volume and low-latency data processing. Samza allows developers to write custom processing logic using the Apache Kafka Streams API or the Apache Samza API.
Kafka the Publisher
There are many terms abstracted in Kafka. Topics are used to categorize messages, with producers publishing to topics and consumers subscribing and reading from topics. Topics are divided into Partitions, which represent units of parallelism and can be used for per-key processing. Brokers handle message persistence and replication, and Kafka uses Replication for fault-tolerance, choosing a leader and followers for each partition. If the leader fails, an alive follower becomes the new leader. This mechanism allows Kafka to tolerate failures.
Publish-subscribe (Pub/Sub) Pattern
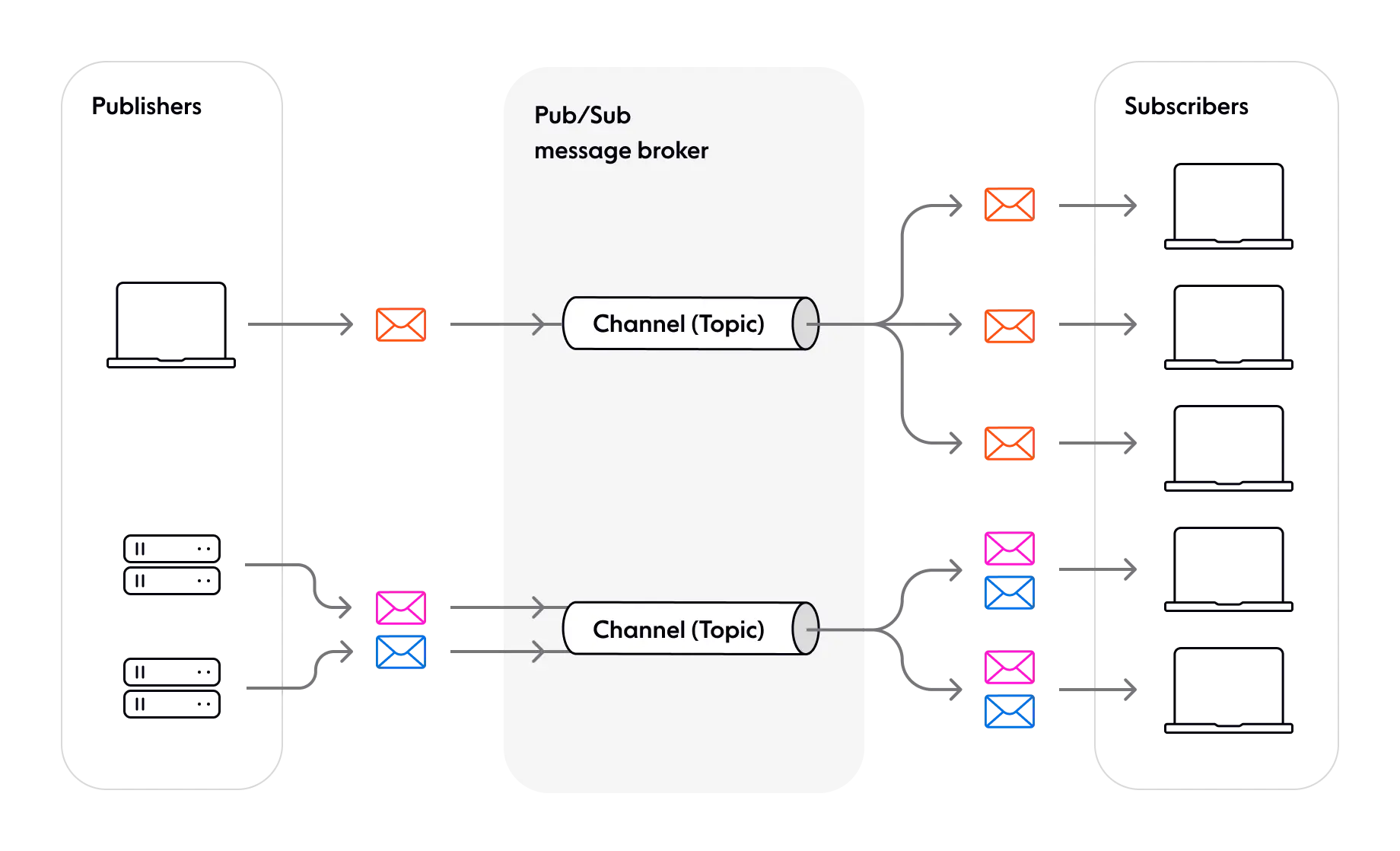
Pub/Sub provides a framework for exchanging messages between publishers (such as a news feed) and subscribers (such as a news reader)[1]. Note that publishers don’t send messages to specific subscribers in a direct end-to-end manner. Instead, an intermediary is used - a Pub/Sub message broker, which groups messages into entities called channels (or topics). [2]
What is Pub/Sub? The Publish/Subscribe model explained https://ably.com/topic/pub-sub. ↩︎
Image is from Ably ↩︎
Sample Kafka Producer (Publisher) Code
The code defines a DataProducer class responsible for sending data to a Kafka topic. It reads a trace file line by line, parses each line into a JSON object, and determines the topic based on the "type" field. The data is then sent to the appropriate topic using Kafka's producer.send() method.
Samza the Subscriber
Samza is a distributed stream processing framework developed by LinkedIn, which is designed to continuously compute data as it becomes available and provides sub-second response times.
Like Kafka, there are also some terms in Samza, a Stream is made up of partitioned sequences of messages, similar to Kafka topics. Jobs in Samza are written using the API and can process data from one or more streams. Stateful stream processing is supported in Samza, where state is stored in an in-memory key-value (KV) store local to the machine running the task. This state is replicated to a changelog stream like Kafka for fault tolerance.
Samza APIs
Samza provides both a high-level Streams API and a low-level Task API for processing message streams.
High Level Steams API
The Streams API allows for operations like filtering, projection, repartitioning, joins, and windows on streams in a DAG (directed acyclic graph) format.
The code defines a class called "WikipediaFeedStreamTask" that implements the "StreamTask" interface. It processes incoming messages by converting them into a map and sends them to a Kafka output stream named "wikipedia-raw".
Low Level Task API:
The Task API allows for more specific processing on each data. Sample code at samza-hello-samza [1] project on GitHub
The sample code on GitHub repoistory at: https://github.com/apache/samza-hello-samza/blob/master/src/main/java/samza/examples/wikipedia/task/ ↩︎
The code is a Java class named WikipediaParserStreamTask that implements the StreamTask interface. It contains a process method that takes in an incoming message, parses it using a WikipediaParser, and sends the parsed result to an output stream. The main method generates some example strings and passes them to the WikipediaParser.parseLine method to demonstrate its functionality.
Explore the working of Samza
Apache Samza is often used alongside Apache YARN, which manages compute resources in clusters. Samza jobs are submitted to YARN, which allocates containers and runs Samza tasks. YARN handles resource allocation, scaling, and fault tolerance. Each task reads data from a partition in the 'dirty' topic, processes it, and produces the results to the 'clean' topic. Samza ensures fault tolerance by restarting failed tasks. This architecture allows for scalable, parallel processing with high availability for real-time data pipelines.
Explain Apache YARN to Beginners
Imagine you have a large cluster of computers working together to process big data. YARN is like the manager of this cluster. Its main job is to allocate the work and resources to each computer in the cluster.
Let's say you have multiple tasks to perform, like analyzing data, running calculations, or processing real-time streams. YARN takes these tasks and divides them into smaller units called containers. These containers represent pieces of work that can be executed on individual computers in the cluster.
YARN keeps track of all the available resources in the cluster, like memory and processing power. When a task needs to be performed, YARN checks the available resources and assigns a container to do the job. It makes sure that each container gets the required resources to complete the task efficiently.
YARN also monitors the health of the containers. If a container fails or stops working, YARN automatically restarts it on another computer, ensuring that the task continues without interruption. This helps in maintaining high availability and fault tolerance.
One important thing about YARN is its flexibility. It can work with different data processing applications or frameworks, like Apache Hadoop, Apache Spark, or Apache Samza. This means you can use YARN to run different kinds of big data jobs on the same cluster, making the most efficient use of your resources.
In summary, YARN is the cluster manager that allocates work to different computers, monitors their performance, automatically handles failures, and allows you to run various data processing tasks on a large scale. It makes big data processing more efficient, scalable, and reliable.
More Readings on Play around with Kafka and Samza
Official example code for Apache Samza on GitHub.
 apache
apacheTutorial to set up an SSH tunnel to debug YARN using Amazon EMR cluster.
